
轻量型Lite-HRNet与onnx输出
最近,项目中需要在终端使用关键点检测,对于模型性能要求相对严苛。在这里我将讲解并记录模型优化的过程,希望对大家有所帮助。
由于终端算力有限,在内存速度与性能需要权衡好,我选择轻量型关键点性能较好的Lite-HRNet作为模型的backbone。下面,将对Lite-HRNet模型与如何输出onnx模型详细讲解。
Lite-HRNet
先给论文地址。轻量型网络大多采用depthwise convolution与pointwise convolution来降低计算复杂度,depthwise convolution无法在通道间进行信息交互,1×1的pointwise convolution承担了通道信息交互的重要角色。但是1×1卷积的计算复杂度是C 2 C^2C
2
,C为卷积通道数,而3×3的depthwise conv的计算复杂度为9 C 9C9C,当网络中出现大量pointwise conv时,会增加模型的计算复杂度,So pointwise conv is costly.为此,Lite-HRNet提出Conditional channel weighting,如图1-b结构。
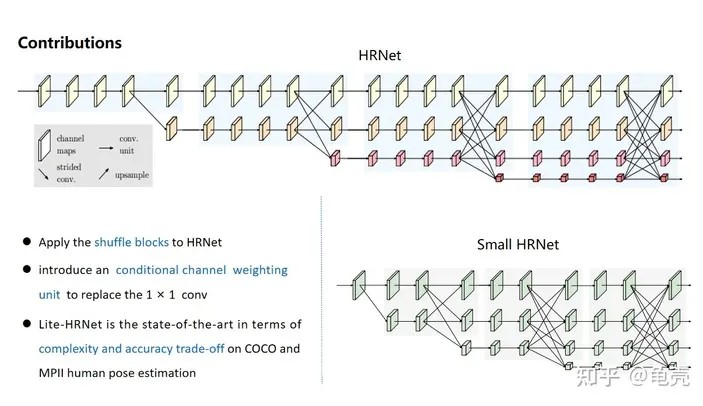
与shuffle block不同,conditional channel weighting block中将1×1 conv替换成cross-resolution weighting function 与spatial weighting function.
Cross-resolution weighting function输入为不同分辨率的feature maps,首先利用自适应平均池化,将不同size的feature maps统一成size最小的尺寸,然后,concate它们并送入1×1卷积中,这里1×1卷积与SE-layer类似,最后,将输出的特征resize成输入相同尺寸的feature,并与输入点成形成最终feature。
class CrossResolutionWeighting(nn.Module):
"""Cross-resolution channel weighting module.
Args:
channels (int): The channels of the module.
ratio (int): channel reduction ratio.
conv_cfg (dict): Config dict for convolution layer.
Default: None, which means using conv2d.
norm_cfg (dict): Config dict for normalization layer.
Default: None.
act_cfg (dict): Config dict for activation layer.
Default: (dict(type='ReLU'), dict(type='Sigmoid')).
The last ConvModule uses Sigmoid by default.
"""
def __init__(self,
channels,
ratio=16,
conv_cfg=None,
norm_cfg=None,
act_cfg=(dict(type='ReLU'), dict(type='Sigmoid'))):
super().__init__()
if isinstance(act_cfg, dict):
act_cfg = (act_cfg, act_cfg)
assert len(act_cfg) == 2
assert mmcv.is_tuple_of(act_cfg, dict)
self.channels = channels
total_channel = sum(channels)
self.conv1 = ConvModule(
in_channels=total_channel,
out_channels=int(total_channel / ratio),
kernel_size=1,
stride=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg[0])
self.conv2 = ConvModule(
in_channels=int(total_channel / ratio),
out_channels=total_channel,
kernel_size=1,
stride=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg[1])
def forward(self, x):
# mini_size = x[-1].size()[-2:]
# out = [F.adaptive_avg_pool2d(s, mini_size) for s in x[:-1]] + [x[-1]]
stridesize_list, kernelsize_list, output_size = self.get_avgpool_para(x)
out = [torch.nn.AvgPool2d(kernel_size=kernel_size.tolist(),stride=stride_size.tolist())(s) for s,kernel_size,stride_size in
zip(x[:-1],kernelsize_list,stridesize_list) ] + [x[-1]]
out = torch.cat(out, dim=1)
out = self.conv1(out)
out = self.conv2(out)
out = torch.split(out, self.channels, dim=1)
out = [
s * F.interpolate(a, size=s.shape[-2:], mode='nearest')
for s, a in zip(x, out)
]
return out
def get_avgpool_para(self,x):
output_size = np.array(x[-1].shape[-2:])
stride_size_list = []
kernel_size_list = []
for index in range(len(x)):
input_size = np.array(x[index].shape[-2:])
stride_size = np.floor(input_size / output_size ).astype(np.int32)
kernel_size = input_size - (output_size - 1) * stride_size
stride_size_list.append(stride_size)
kernel_size_list.append(kernel_size)
return stride_size_list, kernel_size_list, output_size
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
spatial weight function没啥好说的,跟se-layer一样。。。
class SpatialWeighting(nn.Module):
"""Spatial weighting module.
Args:
channels (int): The channels of the module.
ratio (int): channel reduction ratio.
conv_cfg (dict): Config dict for convolution layer.
Default: None, which means using conv2d.
norm_cfg (dict): Config dict for normalization layer.
Default: None.
act_cfg (dict): Config dict for activation layer.
Default: (dict(type='ReLU'), dict(type='Sigmoid')).
The last ConvModule uses Sigmoid by default.
"""
def __init__(self,
channels,
ratio=16,
conv_cfg=None,
norm_cfg=None,
act_cfg=(dict(type='ReLU'), dict(type='Sigmoid'))):
super().__init__()
if isinstance(act_cfg, dict):
act_cfg = (act_cfg, act_cfg)
assert len(act_cfg) == 2
assert mmcv.is_tuple_of(act_cfg, dict)
self.global_avgpool = nn.AdaptiveAvgPool2d(1)
self.conv1 = ConvModule(
in_channels=channels,
out_channels=int(channels / ratio),
kernel_size=1,
stride=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg[0])
self.conv2 = ConvModule(
in_channels=int(channels / ratio),
out_channels=channels,
kernel_size=1,
stride=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg[1])
def forward(self, x):
out = self.global_avgpool(x)
out = self.conv1(out)
out = self.conv2(out)
return x * out
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
在下表中,我们可以看到各个模块的计算复杂度,其中CCW中的spatial weights与multi-resolution weights只有1×1卷积的1/50,大大降低了1×1卷积的计算量。在实际应用中,Lite-HRNet在NCNN的推理时间大概12ms,精度也能满足项目需求。
Lite-HRNet的onnx输出
由于官方代码中使用了自适应的池化函数adaptive_avg_pool2d,导致无法正常导出。需要修改models\backbones\litehrnet.py,将其中的自适应池化函数改为正常的池化函数,因此需要计算出正常池化函数的几个参数:核大小kernel_size、步长stride_size、填充padding(一般都是0,可以忽略这个参数)。修改其中的CrossResolutionWeighting类的forward。
class CrossResolutionWeighting(nn.Module):
"""Cross-resolution channel weighting module.
Args:
channels (int): The channels of the module.
ratio (int): channel reduction ratio.
conv_cfg (dict): Config dict for convolution layer.
Default: None, which means using conv2d.
norm_cfg (dict): Config dict for normalization layer.
Default: None.
act_cfg (dict): Config dict for activation layer.
Default: (dict(type='ReLU'), dict(type='Sigmoid')).
The last ConvModule uses Sigmoid by default.
"""
def __init__(self,
channels,
ratio=16,
conv_cfg=None,
norm_cfg=None,
act_cfg=(dict(type='ReLU'), dict(type='Sigmoid'))):
super().__init__()
if isinstance(act_cfg, dict):
act_cfg = (act_cfg, act_cfg)
assert len(act_cfg) == 2
assert mmcv.is_tuple_of(act_cfg, dict)
self.channels = channels
total_channel = sum(channels)
self.conv1 = ConvModule(
in_channels=total_channel,
out_channels=int(total_channel / ratio),
kernel_size=1,
stride=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg[0])
self.conv2 = ConvModule(
in_channels=int(total_channel / ratio),
out_channels=total_channel,
kernel_size=1,
stride=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg[1])
def forward(self, x):
# mini_size = x[-1].size()[-2:]
# out = [F.adaptive_avg_pool2d(s, mini_size) for s in x[:-1]] + [x[-1]]
stridesize_list, kernelsize_list, output_size = self.get_avgpool_para(x)
out = [torch.nn.AvgPool2d(kernel_size=kernel_size.tolist(),stride=stride_size.tolist())(s) for s,kernel_size,stride_size in
zip(x[:-1],kernelsize_list,stridesize_list) ] + [x[-1]]
out = torch.cat(out, dim=1)
out = self.conv1(out)
out = self.conv2(out)
out = torch.split(out, self.channels, dim=1)
out = [
s * F.interpolate(a, size=s.shape[-2:], mode='nearest')
for s, a in zip(x, out)
]
return out
def get_avgpool_para(self,x):
output_size = np.array(x[-1].shape[-2:])
stride_size_list = []
kernel_size_list = []
for index in range(len(x)):
input_size = np.array(x[index].shape[-2:])
stride_size = np.floor(input_size / output_size ).astype(np.int32)
kernel_size = input_size - (output_size - 1) * stride_size
stride_size_list.append(stride_size)
kernel_size_list.append(kernel_size)
return stride_size_list, kernel_size_list, output_size
感谢 小小小绿叶
